2023 Reengineering Project - LinkedIn/Kafka
(Last Update: 2023-03-20)
Target Application
LinkedIn project is a variant fork of Apache Kafka running at LinkedIn.
Kafka was born at LinkedIn. The run thousands of brokers to deliver trillions of messages per day. They run a slightly modified version of Apache Kafka trunk. The LinkedIn variant contains the LinkedIn Kafka release.
Assignment
1. Contextualization for Strategic Refactoring
LinkedIn is a clone-and-own variant of Apache Kafka that was created by copying and adapting the existing code of Apache Kafka that was forked on 2011-08-15T18:06:16Z. The two software systems kept on synchronizing their new updates until 2022-02-22T13:32:39Z. Since 2022-02-22T13:32:39Z (divergence date), the two projects do not share common commits yet actively evolve in parallel. For example, as of 2022-02-28T15:01:39Z, LinkedIn has 500 individual commits, and Apache Kafka has 3,103 individual commits. Development becomes redundant with the continued divergence, and maintenance efforts rapidly grow. For example, if a bug is discovered in a shared file and fixed in one variant, it is not easy to tell if it has been fixed in the other variant.
General problem illustration. The figure is an illustration of clone-and-own, where variant2 (forked repository) was cloned-and-owned from variant1 (original repository). When variant2 was created (fork_date), it inherited all commits from variant1. Then, between the fork_date and divergence_date, both variants synchronised commits with each other, keeping both variants even. After the divergence_date, the variants stopped synchronizing commits.
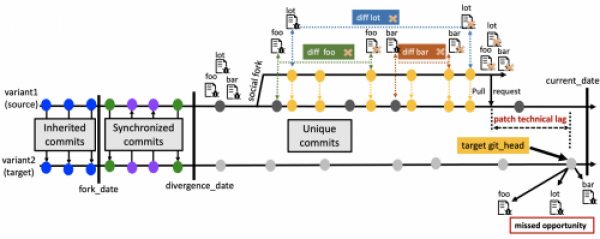
Let us assume that the developer of variant1 identified a bug after the divergence_date that is spread across files foo, bar, and lot. The developer then decided to create a social fork or a branch of the source repository, patched the buggy files, and finally integrated the patch back into the main branch of the source repository using a pull request. There are four possible scenarios on the git_head of variant2.
- The developer of variant2 could have patched the buggy file in one of the previous commits before the commit at the git_head. This is a case of effort duplication (ED).
- The file at the git_head of the target still contains the buggy lines. This is a case of missed opportunity (MO). We can even calculate how long the target branch has missed the patch by calculating the distance between the patch integration date and the current date of the git_head.
- The file at the git_head of the target contains both the buggy and the patched lines. In this case both effort duplication and missed opportunity are present. This is a split case (SP).
- The file at the git_head of the target does not contain both the buggy and the patched lines. So this case would not be interesting (NI).
There is a clone detection tool developed in our group, PaReco, that can extract patches from any source variant ( e.g., Apache Kafka) in a family and classifies the patches as a MO, ED, SP, or NI in the target variant (e.g., LinkedIn). The file patches.xls contains patches (MO and SP) that have been identified in the source variant Apache Kafka that are missing in the divergent target variant LinkedIn.
Your assignment is to identify numerous patches from patches.xls that are of different sizes and integrate them in the source variant LinkedIn. The size can be measured in terms of number of commits, files_changed, added_lines, deleted_lines, modules.
Since the the fork has diverged, it is possible that it has changed the shared file(s) where the patch is located in the upstream. Therefore, while performing the integration, you might experieince some merge conflicts. This paper is an interesting read since it does something similar to what you will be doing. In the paper the authors describe the nature of merge conflicts that arise due to merges from upstream and classify them into textual conflicts, build breaks, and test failures. The authors also describe a tool that performs automated merging. While performing patch integration into your fork, you may find the git tools of cherry-picking and squashing of commits useful.
2. Getting Started Instructions
Please pay attention to the following instructions. You need to send an email to Onur Kilincceker and Mutlu Beyazıt with the following.
- Subject
- "Reengineering 2023 - LinkedIn/Kafka" if you intend to work on this suggested software; or
- "Reengineering 2023 - Custom Project" for a custom project proposal. Please try to contact us sooner than the deadline (March 22, 2023) if you want to work on a custom project.
- Message Body
- The full name of the members in your group (including yours). Remember, a maximum of 3 people but you are allowed to work with less than 3 if you want to.
- If you choose to work on a custom project, then you will need to explain/motivate why this project would allow you to demonstrate your reengineering skills.
- Attach the pre-conditions report (PDF format) in your message.
Your Pre-conditions Report should contain the following.
- Project Name (to be sure you are working on the suggested project or a custom one)
- Full Name of all the members in your group
- Link to your GitHub repository (which show to us you already forked LinkedIn)
- The members are set as collaborators to the GitHub project.
- The teaching assitants are invited as collaborators (Onur's GitHub Id and Mutlu's GitHub Id).
- If you plan to automate the integration exercise, it is advisable to create a separate GitHub repository to host the automated patch integration tool. Please invite all asistants as collaborators.
- Demonstrate the ability to build the project. For this, we want a statement from the group attesting they managed to successfully build the project. You can also attach a screenshot of your IDE with the project source and a message like "build successful".
- Simple Class Diagram of the class being patched (or buggy class). A simple class diagram has only the name of the class and its interactions with the other classes (there are two examples in JPacman repository in the "docs" folder). This is to reinforce your initial understanding of the system. You only need to focus on the classes associated with the patch and the classes that are called in those classes. There is no need to go deeper into the class structure (i.e., if buggy class calls Class X, and Class X calls Class Y, then you do not need to show Class Y since it is not being called directly by the buggy class). We are not going to evaluate your strictness to the proper UML notations, therefore focus on modeling and understanding classes interactions.
- For custom projects, this will be a Simple Class Diagram of your system. If your system is big, we can negotiate a smaller subset of the system for this diagram. In any case, you will need to contact the TAs sooner to set up the details.
- [Optional] A rough planning of the scope and goals. As you noticed the project refactoring is open to interpretation (this is on purpose). Therefore, is up to you, students, to plan the scope for your project. It is entirely possible for different groups to have different scopes and planned activities based on this assignment.
3. General Coding Instructions
In order to work on this assignment, the following coding/repository instructions apply.
- Fork LinkedIn, and clone the source code for your team to work on it. In the Documentation webpage, you can find further instructions on how to build the software (adapt accordingly, as many open source projects are a bit careless with keeping their documentation up-to-date).
- If you are working on this assignment as a group, then all members should be added to the repository as collaborators.
- Add the teaching assistants as collaborators to your fork (See above for the Ids).
- Commit/push your changes regularly providing information on the activity performed. Any "single" activity that requires file maintenance must be committed as a single commit with a simple description of the maintenance performed. For example, if you change the system to refactor class Y, your commit should be
fixing merge conflicts on patch X, class Y or unit tests for class Y.
Another example, let's suppose you also introduced new tests along with the refactoring
refactoring Class Y to add the patch + new tests added
Of course, pushing the tests on a separate commit would also be acceptable (actually, it would be better to do so).
It is not considered good practice to commit a big chunk of modified files without providing a reason that explains why those files have been modified. Therefore, try to split your commits into smaller units (that may help with the grading).
Your GitHub commit history will be evaluated. Therefore be sure to commit and push regularly.
Be sure to commit/push the final version of your reengineering project before the final deadline. The final commit will be considered for evaluation as part of your assignment submission.
4. Development Activities
Then, more specifically, we ask you to perform the following activities, and report about these in your project report.
[I. Design recovery]
Describe the current design implementation of the selected feature in the current Software. Clearly indicate how this design is located in the architecture of the project.
[II. Redesign]

Compose a generic design that describes how the new functionality / feature should be integrated and how the design handles the interaction with the rest of the system. It should be clear that the new design not only supports the new feature but also does not severely impact the code quality.
It will be necessary to redesign the test suite in such a way that it can cope with the new feature and design.
[III. Management]
Estimate the effort required for (i) refactoring towards the new requirements; and (ii) changing/extending the tests.
[IV. Refactoring]
Refactor the current implementation of the Software such that it can handle the new feature.
Adjust/extend the tests of the project to preserve their effectiveness and coverage during and after refactoring.



You will be required to perform a number of techniques presented during the lab sessions. These are as follows.
- Analyzing: Metrics and Visualization; Duplicated Code Analysis; and Mining Software Repositories.
- Restructuring: Testing; and Refactoring. Please use the techniques that you deem applicable to your problem. You need to convince us in the report why you decided to use/exclude some of the techniques.
This project emphasizes the sound, systematic analysis of the presented problem, the associated solution space, and the chosen solution(s). The software reengineering sessions are composed in such a way as to prepare you for such a project. We stimulate you to assess the benefits and drawbacks of the techniques presented in the lab sessions and ask you to exploit the analysis techniques wisely. You are free to use alternative analysis techniques and tools as much as you deem necessary.
What concerns the refactoring-part, we emphasize the use of tests. Our minimum requirements are given below.
- Determine the extent to which the current tests provide feedback on your future refactoring-steps. Quantify this (i.e., show coverage information).
- Compose an argument discussing why the tests are adequate/inadequate for your chosen refactoring scenario. If inadequate, adjust the tests as needed. Be efficient with regard to the time invested in testing.
5. General Evaluation
To show that you have passed the assignment, you will have to demonstrate the following.
- You possess the knowledge to plan and selected the appropriate reengineering patterns for your project activities.
- You have made a selection of analysis techniques (e.g., duplicated code analysis, mining software repositories, metrics and visualization as seen in the lab sessions, but others are allowed as well), and have applied these techniques in a sound, systematic manner. You have indicated clearly (using screenshots, results of the interpretation of the output of the techniques) how you have used the results of these analysis techniques.
- You have performed the above activities (decomposed into (i) Design Recovery; (ii) Redesign; (iii) Management; and (iv) Refactoring) and discussed them in your project report.
- The restructurings you have applied are behavior preserving:
- You can demonstrate the mapping between each of the classes from the original structure with the new structure.
- The compilation process succeeds flawlessly.
- The tests run without flaws and show increased testing coverage making it more reliable.
- The introduction of the new design clearly indicates the project is ready to be released in a language of choice. You are not supposed to carry out the refactoring process completely. Select and execute a set of refactorings that sufficiently illustrate your proposed solution.
- The report is written in a clear manner detailing all the steps and reasoning for the project. Remember that the report is the document that registers all your work. Thus, it is the most important artifact for the evaluation process.
For a more precise on-point view of the evaluation criteria, please look over the check-list (for each report) on the course's main page.
6. Report
Aspects that we typically like to see addressed in the final report are as follows.
- Context: Briefly discuss the context in which you are running your project (do not just copy verbatim the text on 1. Contextualization).
- The Problem at Hand: Clarify the problem at the base of the project, and indicate its intrinsic difficulties (again, do not just copy the assignment problem description, elaborate based on your chosen interpretation, goals, and scope).
- Reengineering Patterns: You explicitly state the patterns (from the OORP book) that you selected and used throughout the project.
- Project Management: Demonstrate how you have organized the work, and how you are controlling it (instead of the work controlling you!)
- Scope: What are the boundaries of your project? What is not included in the project?
- Risks: Which risks were envisioned, and which have been mitigated? What is the priority of the risks that still need to be mitigated? E.g., which external dependencies might have an effect on your outcome? Which alternatives have you prepared in case this risk instantiates?
- Software Reengineering
- Tests: How can you verify that you satisfy the requirements? Which testing strategy have you selected, and what are the arguments for this selection? How confident are you that your solution satisfies the requirements?
- Quality Assurance: What are the non-functional requirements? E.g., how do you differentiate between a good and a bad solution?
- Refactoring: Which refactorings did you perform on the project? Why is it better now? How does your refactoring help to support the new intended features?
Those are aspects we like to see addressed/tackled/discussed/explained/presented in the Final Report. In the Intermediate Report, we expect less detail. However, groups that try to start addressing some of the above concerns most often have a better Intermediate Report. In the Pre-conditions Report, although not necessary, it might be better if your group starts to plan the scope and goals for the project.
Please also keep in mind and check the Report Guidelines and the Evaluation Checklist on the main page.
7. Final Remarks
If you have any questions about the project or the report, please contact the teaching assistants.
It is possible to submit your own project proposals based on LinkedIn/Kafka or another software system. These proposals will be approved in case they provide a well-structured exercise on the reengineering techniques presented in the lab sessions.
This project is slightly modified from 2022 Reengineering Project. If problems arise, you may use the original date of the 2022 Project to determine the versions of the tools and the software which work together.